AllTogether: Avatars in Mixed-Modality Conferencing
Let's use avatars as a way to bridge the binary extremes of camera on/off typical in video conferencing. I created many avatar variants for people to try, from visually abstract to realistic, and from tracked movements to synthetic.
Panda, P., Nicholas, M. J., Gonzalez-franco, M., Inkpen, K., Ofek, E., Cutler, R., Hinckley, K., & Lanier, J. (2022). AllTogether: Effect of Avatars in Mixed-Modality Conferencing Environments. 2022 Symposium on Human-Computer Interaction for Work (CHIWORK 2022).
🌐https://doi.org/10.1145/3533406.3539658
📄download paper
Introduction
Visual representation in most video conferencing systems is a binary option between camera on and off. With such systems, voice-only participants might feel left-out, particularly in configurations that situate video participants in a shared virtual environment. We developed a system that provides voice-only participants with the option to be represented by an avatar in a call with other video participants. Past research has compared the effect of avatar representations with video and audio, but focused on single-modality calls (i.e. all participants represented as either avatars or video or audio only). We studied the use of our system across three conferencing sessions with 9 participants being represented by a mixture of avatar, video, or voice-only (no visual) representations to better understand users’ perceptions and feelings of co-presence when being represented through these modalities.

We found that the visual representation of self and others as well as body motion agency affected participants' feelings of co-presence and the level to which participants felt others were present in the video call respectively. Our results highlight the implications of visual realism and agency of control on users' perception of self and others. We propose avatars as a way to expand the binary choice of camera on and off to a spectrum of choices for the user, offer design implications for integrating avatars into video conferencing systems, and update the literature on users' avatar preferences.
Avatar software and setup
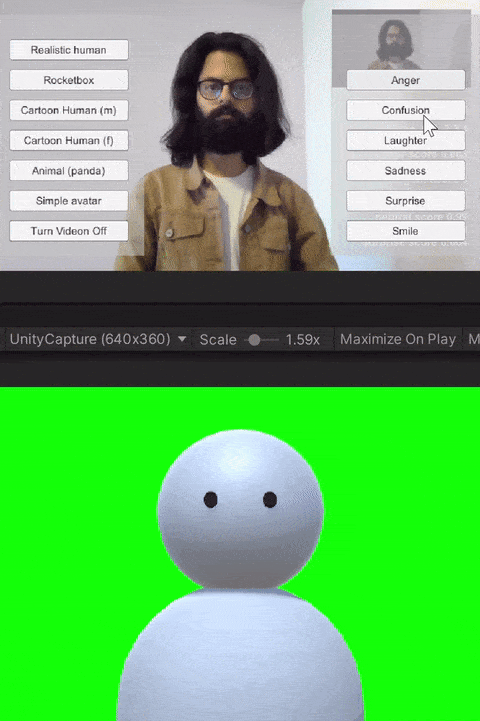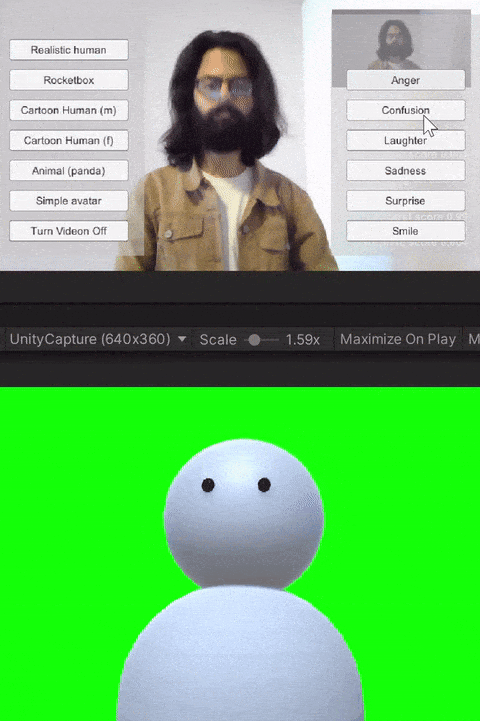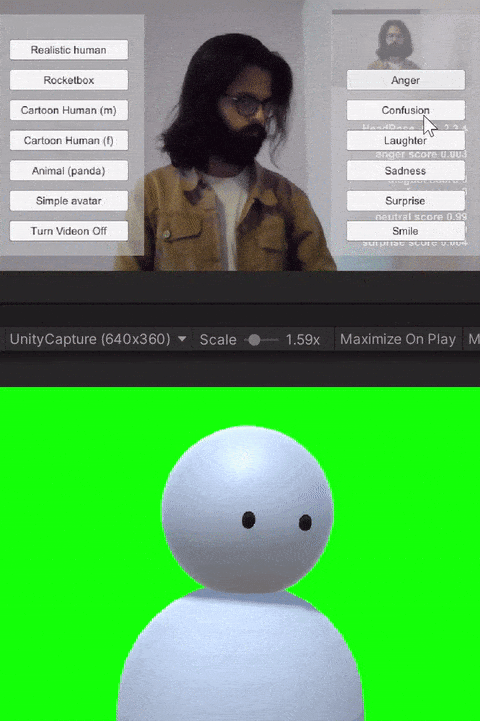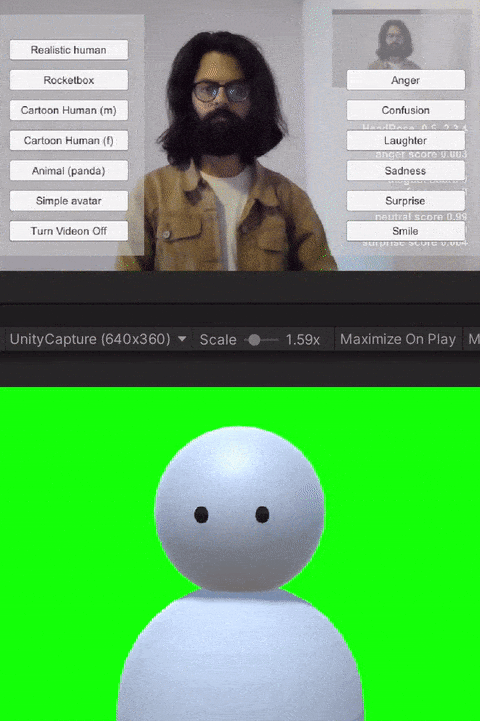
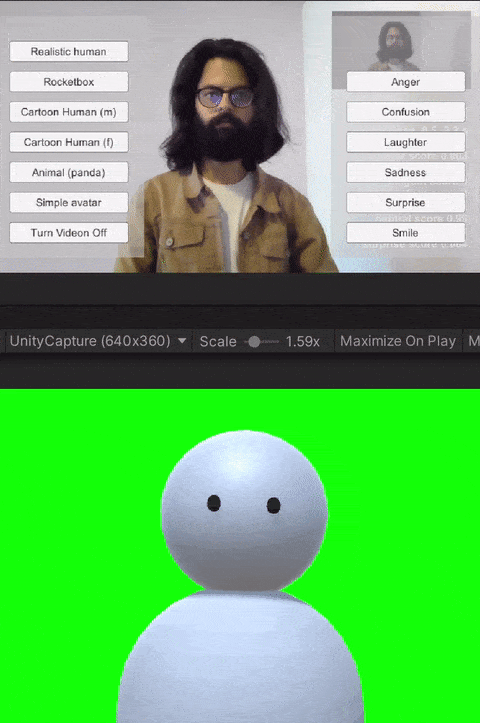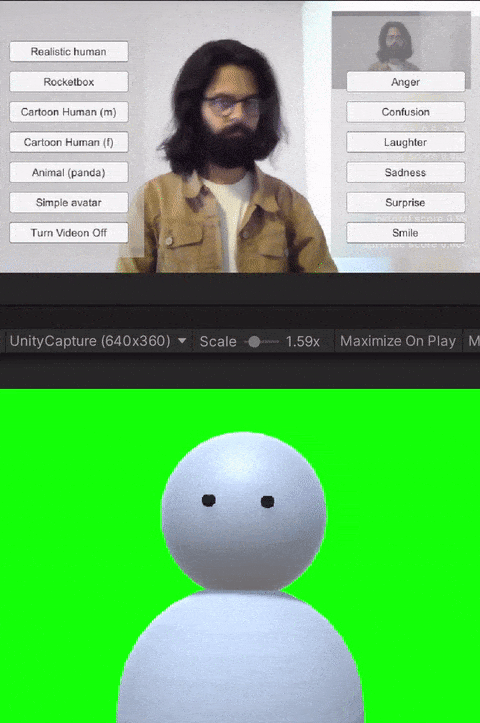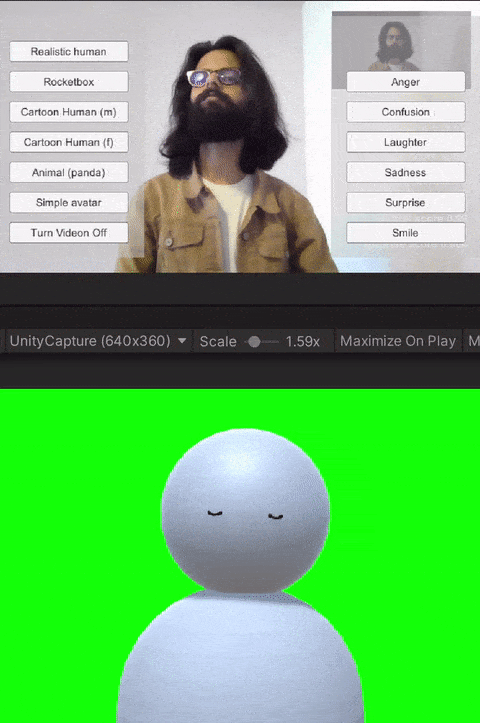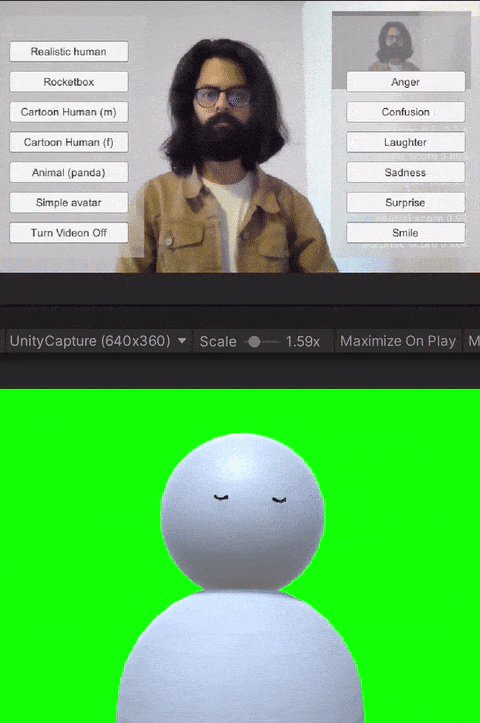
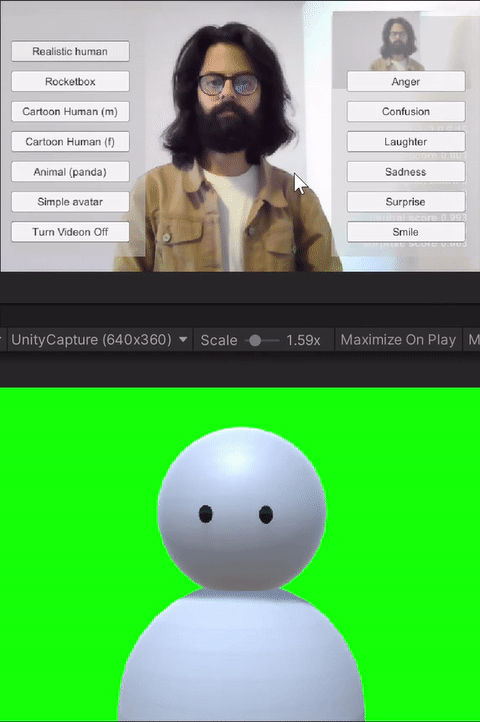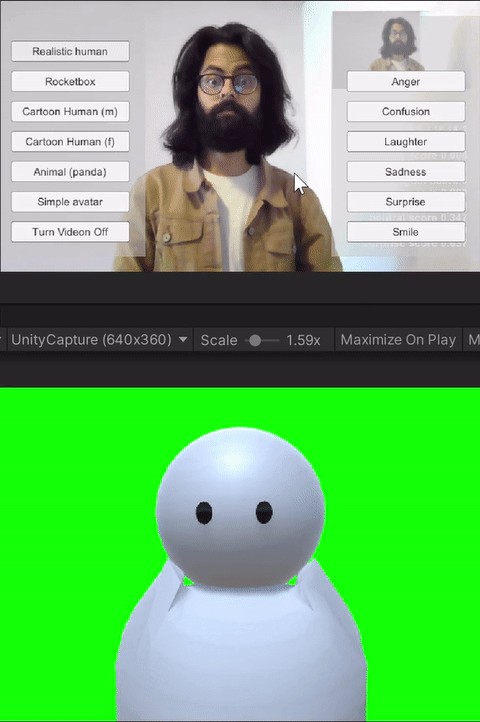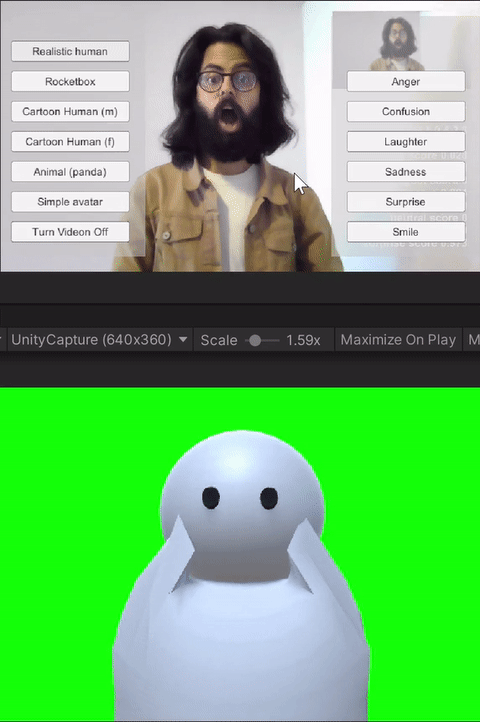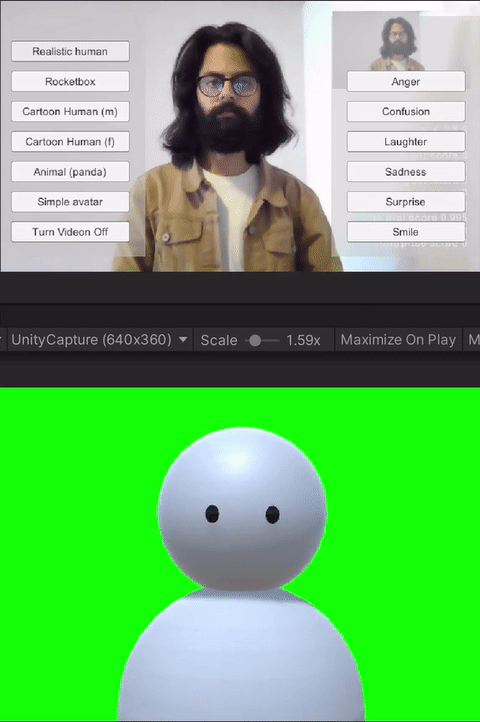
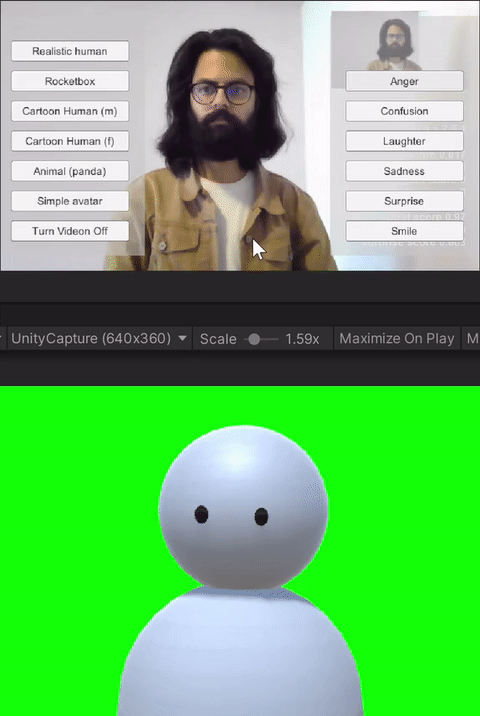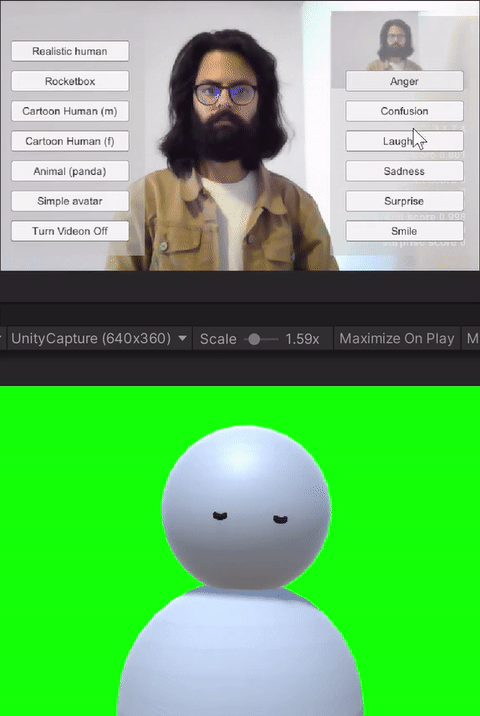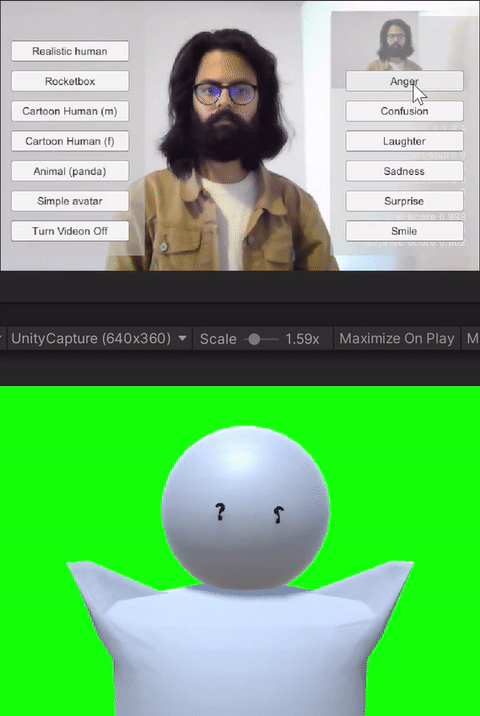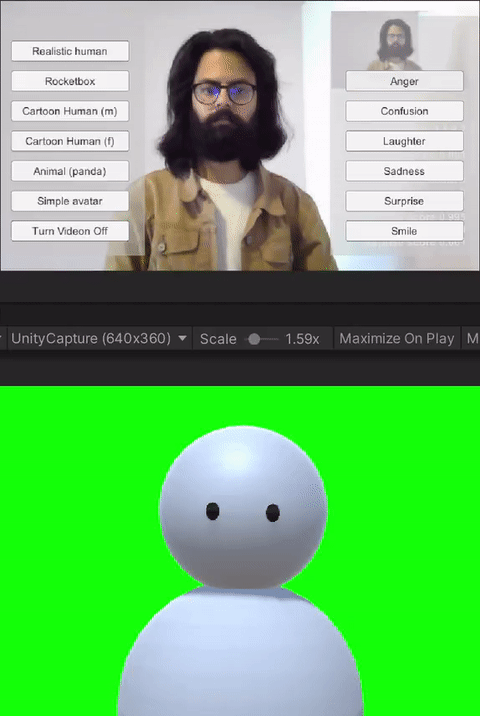
For the study, we built custom client-side avatar software in Unity3D game engine that interfaces with Together mode in Microsoft Teams. Together mode was chosen because it offered a shared virtual space that could be inhabited by video participants, avatars, and audio participants at the same time. Each participant that was assigned the avatar condition for the session ran this software on their machine. Using this software, participants could choose an avatar to represent themselves and switch between different avatars on the fly. The system allows for the avatar to either be controlled through motion capture from a webcam, or to generate artificial movements. In addition, it allows users to trigger emotions expressed through facial and body movements selected on a point and click interface. Our software runs the avatar in the background and we use an open-source Windows DirectShow filter, Unity Capture, to broadcast frames from our software as a virtual camera. The participant then chooses this virtual camera in Microsoft Teams.
Avatar visual fidelity
The avatar choices given to the participants had different levels of visual fidelity, representing different levels of realism. The high visual fidelity avatars were visually photorealistic, with a strong resemblance to the participant. These were generated from the participant's photograph using an online service. For the remaining avatars, their resemblance to humans receded as the avatars became more abstract. These avatars were created by the authors in Unity3D using simple geometric shapes like spheres, capsules, and boxes. Four levels of fidelity were provided to the participants: 1) realistic human; 2) cartoon human (male or female); 3) animal (panda); and 4) simple generic avatar. Participants were allowed to choose their desired level of fidelity.

Avatar motion fidelity
Two levels of body motion were also implemented for the avatars. Avatar head motion was either mapped to the participant's head movements sensed through webcams for high motion fidelity, or was synthetically generated by the software. For the synthetic motion, the avatars randomly looked in different directions at irregular intervals, creating low motion fidelity.
The motion fidelity of the avatar was assigned to each user, with half using head-movement and the other half using synthetic motion. For the head-mapped motion, we used the OpenPose library. OpenPose can detect key landmarks on the user's face on a 2D plane. We implemented a simple algorithm to estimate the 3D head pose from the 2D location of the landmarks. This mode required access to a camera device.
Avatar expression fidelity
The avatar software allows users to trigger basic emotions through a point-and-click interface. The expressions available to the users are anger, laughter, sadness, smile, and surprise. These were selected by the research team based on which expressions we would like to have access to for both personal and workplace video calls. In addition to the triggered expressions, the avatars also had idling animations like eye blinks. Additionally, all avatars reacted to the audio from the microphone--including lip-sync for avatars with lips, and other visual indicators (e.g., a scaling head) for low visual fidelity avatars without a mouth.
Implications
Avatar customizability
Giving users the agency to choose between avatars of different visual fidelity and the option to customize these avatars for personalization and easier identification has merit.
Avatars with different levels of fidelity can be useful in different circumstances, like a non-realistic, simple avatar in a large video call as an audience member, or a realistic avatar for a team meeting at work. Combined with the different options for enabling avatar movement (body tracking, synthetic motion), we can create a rich ecology of choices for call participants. Each of these choices will have pros and cons (eg. higher trust of tracked avatars (from the observer's perspective), but higher freedom to do other work during the call with avatars with synthetic motion (for the actor)). A conferencing system could potentially suggest different avatar visual and tracking fidelity for the user based on the context (e.g. low fidelity avatars for large meetings, high fidelity for small meetings, video for 1:1 meetings).
A participant represented by a more realistic avatar was easier to identify, accepted by the other participants, and regarded as more reliable. However, study participants that sought privacy through avatars felt exposed by using realistic avatars. While it was harder to distinguish low-fidelity avatars from each other, offering personalization for such avatars could aid in differentiating between participants while retaining user privacy.
Alternate input tracking methods
In our study, avatars either had synthetic motion, or motion tracked through the camera. Participants noted the benefits of having tracked motion, saying that it makes the avatars feel more natural. However, there were advantages of offering synthetic motion--e.g. being visually present in the call while not being tied to the physical location of the computer. A good synthetic motion model that does not require direct sensing of the users may address the needs of realism and privacy. However we suspect that a naive implementation of such a synthetic motion algorithm might lower presence.
The implementation we tested in this paper does not allow the user to have tracked motion without being physically present in front of a camera. However, there can be other ways of tracking user's movements. For example, headphones with a built-in Inertial Measurement Unit (IMU) could be used to track a user's head movements, which can enable the avatar to mimic the participant's motions. These augmented headphones could allow for tracked movements even while the user might be physically located elsewhere. Here's an example (link) of some work I've done along these lines since then.

These forms of input tracking relate back to one of the reasons for users turning their video off: "I wanted to multitask during the meeting" was chosen as a reason by 13% of the respondents in our formative survey. Avatars that allow such users to do other tasks, such as laundry or house chores, could allow them to have visual presence in large group calls while enabling them to accomplish other tasks.
Graceful bandwidth degradation
One of the major reasons that users turn off their video cameras is the network bandwidth that video sharing demands. Using avatars can be an advantage to people without access to a high-speed internet connection. Since avatar movements are computationally controlled, the avatars can be implemented in the cloud for server-mediated video conferencing solutions like Microsoft Teams, or individually on the client side for peer-to-peer (P2P) video conferencing like Skype. This reduces the amount of data that a user has to upload in order to communicate. For synthetic motion the user only has to upload audio, and for tracked motion it is sufficient to transfer movement data only which can be used to compute the avatar's representation on the server or on the client side. Avatars can also be beneficial for graceful bandwidth degradation. Compression and downsampling the video stream are common practice in video conferencing solutions. For video conferencing, avatars can provide most of the benefits of full visual fidelity (video, high bandwidth usage) at a bandwidth cost similar to audio-only transmission. When the user's network speed drops, the video conferencing system can automatically and gracefully transition from video to avatar.